Inspired by Andrej Karpathy’s LLM Wiki and extended into an enterprise architecture for centrally governed, continuously improving organisational knowledge.
Last week, Andrej Karpathy published a brilliant gist called LLM Wiki — a pattern for building personal knowledge bases where an LLM incrementally writes and maintains a wiki from raw sources. Instead of the traditional RAG approach — retrieve, hope for the best, and re-derive knowledge on every question — the LLM compiles knowledge once into structured, interlinked markdown pages and keeps them current as new information arrives.
The core insight is deceptively simple: humans are great at curating sources and asking the right questions; LLMs are great at the bookkeeping nobody wants to do — summarising, cross-referencing, filing, and maintaining consistency across dozens of pages. The knowledge compounds over time rather than being rediscovered from scratch on every query.
Thank you, Andrej, for articulating this pattern so clearly. It fundamentally reframes how we think about organisational knowledge — not as a retrieval problem, but as a maintenance problem that LLMs are uniquely suited to solve.
Reading that gist, I couldn’t stop thinking: what if this wasn’t just personal? What if every developer’s AI agent — Claude Code, GitHub Copilot, Cursor, Codex, Gemini — could tap into a single, centrally governed, continuously improving knowledge base?
Not a chatbot. Not a search engine. A living wiki that AI agents consult before writing code, reviewing pull requests, or answering questions about an organisation’s conventions.
Here’s the architecture I’ve been designing. It’s a thought process — not an implementation guide. I’m sharing it to get feedback, poke holes, and refine it before building.
The Problem: Tribal Knowledge Dies in Slack Threads
Every engineering organisation has the same problem. The real knowledge — how you name things, which error handling patterns you use, why you chose Terraform over Pulumi, what your CI/CD pipeline expects — lives in people’s heads, scattered Slack messages, forgotten Confluence pages, and code review comments nobody will ever find again.
New developers spend weeks discovering conventions through trial and error. AI coding assistants give generic answers because they don’t know your organisation’s specific decisions. Code reviews become repetitive as the same feedback gets given over and over. Standards exist, but nobody maintains them because the maintenance burden always loses to shipping features.
What if the maintenance was close to free?
The Idea: A Centrally Managed, LLM-Maintained Wiki Served to Every Developer’s AI Agent
The architecture has three main components.
1) A Git Repository as the Single Source of Truth
The wiki lives in a dedicated Git repository — just markdown files, organised by domain: coding standards, CI/CD patterns, security policies, testing conventions, and architecture decisions. Every change is a commit. Every commit has an author. Every merge goes through a pull request with CI validation.
This isn’t a database or a SaaS product. It’s the simplest, most durable format possible: files in version control.
An admin team — platform engineering, security leads, architecture owners — curates the wiki. They add raw source documents such as RFCs, post-mortems, audit reports, and vendor documentation. An LLM processes each source, extracts key information, and weaves it into the relevant wiki pages. Add a security audit report, and the LLM updates the right security pages, flags contradictions with existing guidance, and cross-references related standards. The admin reviews the proposed changes in a pull request, and CI validates that everything remains consistent.
2) An MCP Server as the Delivery Layer
This is where things get interesting.
Instead of copying the wiki into every project repository, a lightweight MCP (Model Context Protocol) server sits between the wiki and every developer’s AI agent. The MCP server clones the wiki repository, stays current via webhooks, and exposes the wiki as tools that any AI agent can call.
Typical capabilities would include:
- Search the wiki for relevant pages
- Read specific wiki pages in full
- Review code against organisational standards, returning concrete violations with citations
- Suggest missing topics when the wiki has a gap
The developer configures their AI agent with a single MCP endpoint — that’s it. Whether they use Claude Code, GitHub Copilot, Cursor, Codex, or another MCP-compatible agent, they get the same organisational knowledge. The wiki remains fresh because the MCP server auto-pulls on every merge to main.
3) A Developer Feedback Loop with Guardrails
This is the part I find most compelling.
Developers shouldn’t just consume knowledge — they should help improve it. But not directly, and not without controls.
When a developer’s AI agent queries the wiki and discovers a gap, it can file a lightweight suggestion — a one-line signal that says, in effect, this topic needs coverage. That suggestion goes to a separate, unprotected branch — ideally an orphan branch with no relationship to the main wiki history — so the protection rules on the authoritative branch remain clean and intact.
If multiple developers independently hit the same gap, the suggestion accumulates votes. Once three or more unique developers have flagged the same missing topic, the system promotes it. An LLM drafts a full wiki page, creates a proper feature branch from main, and opens a pull request for admin review. The admin refines it, adds source references, and merges.
Small insights from one developer stay harmlessly in the backlog. Shared knowledge gaps surface automatically and get addressed.
Architecture at a Glance
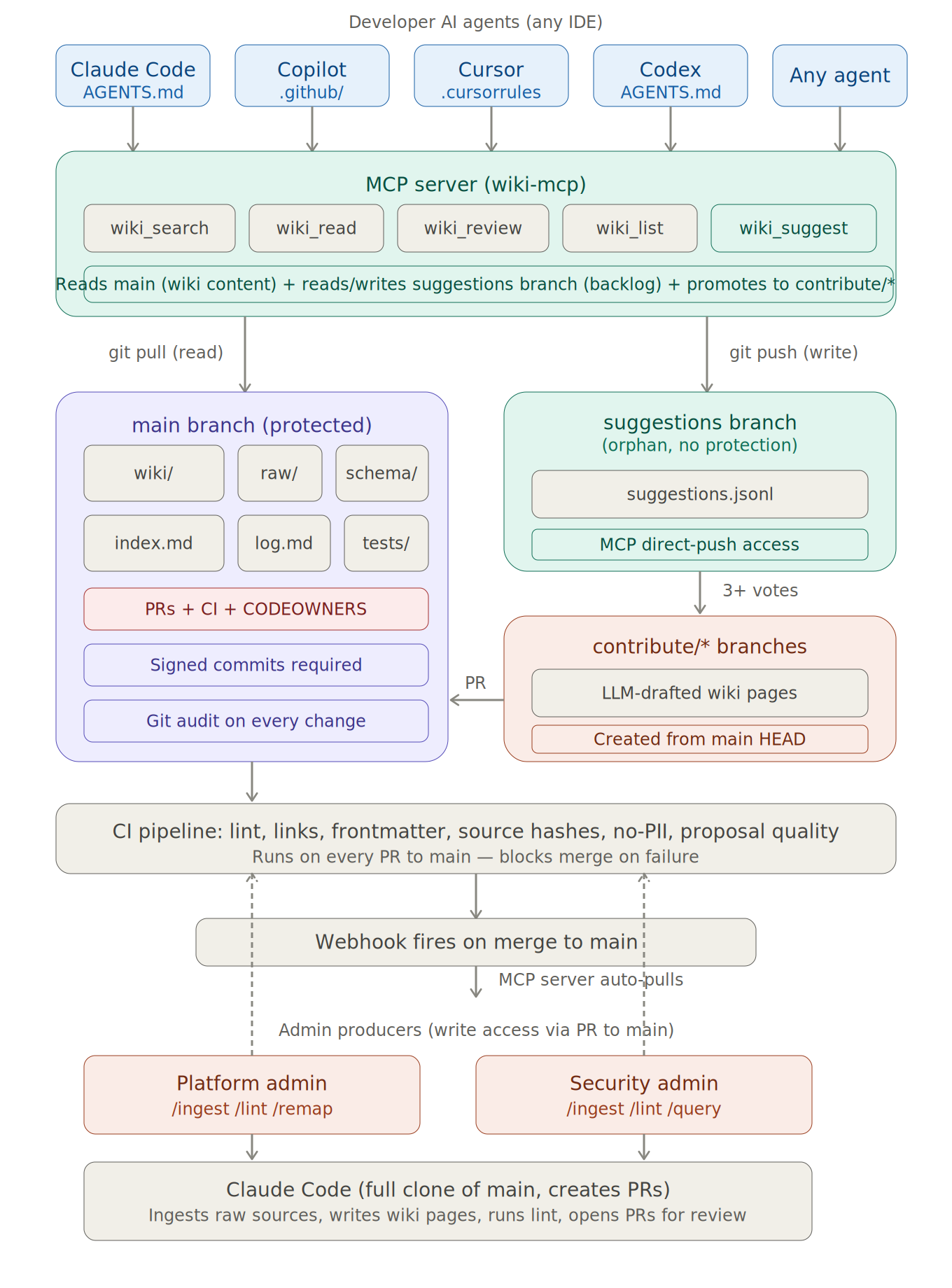
Architecture overview: Developer AI agents connect through the MCP server gateway. The protected main branch holds the authoritative wiki. A separate suggestions branch collects developer feedback without touching the authoritative content. Promoted suggestions flow through feature branches into admin-reviewed pull requests.
The Feedback Loop: From Developer Query to Shared Knowledge
Here’s a concrete example.
Step 1: A developer asks their AI agent: “What’s our convention for retry logic in MuleSoft error handlers?”
Step 2: The agent queries the wiki via MCP. It finds the general error-handling page and the MuleSoft patterns page, but neither covers retry-specific patterns. There’s a gap.
Step 3: The agent answers the developer using general reasoning and the best available context, but it also calls something like wiki_suggest, filing a one-line suggestion: Retry patterns for MuleSoft error handlers.
Step 4: Over the next two weeks, three other developers independently ask similar questions. Each time, the suggestion’s vote count increments.
Step 5: Once the threshold is met by unique contributors, the system promotes the suggestion. An LLM drafts a full wiki page, creates a feature branch, and opens a pull request.
Step 6: A platform admin reviews the PR, adds a production-grade example from real MuleSoft flows, adjusts the guidance based on lived experience, and merges.
Step 7: The webhook fires. The MCP server pulls the updated wiki. Every developer’s AI agent now knows the retry convention.
The next developer who asks never hits a gap. The knowledge has compounded.
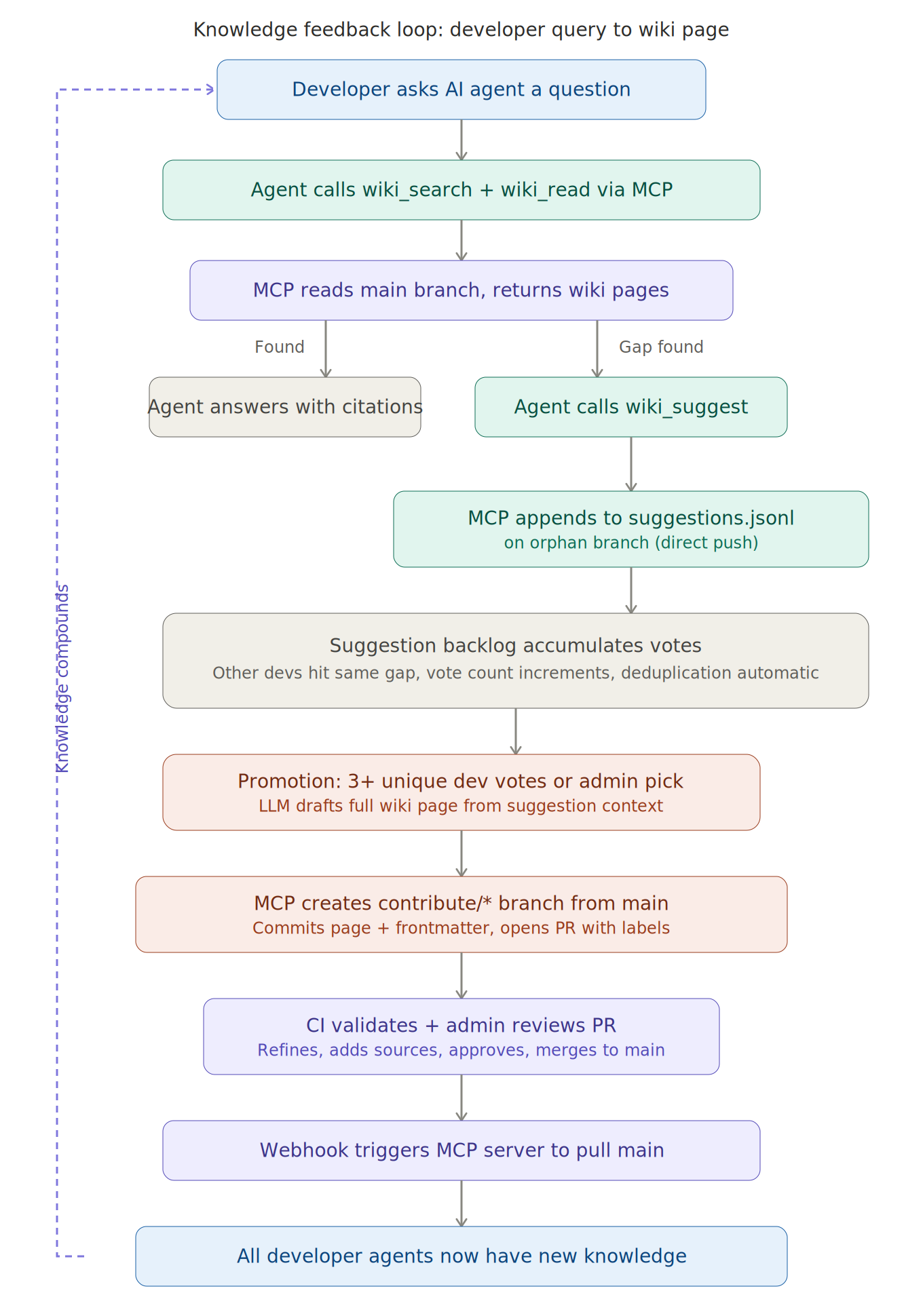
The complete feedback loop: a developer query surfaces a knowledge gap, the suggestion accumulates cross-developer votes in an isolated branch, promotion triggers an LLM-drafted page through admin review, and the updated wiki propagates to all agents via webhook. Every cycle improves the next answer.
Why This Matters for Business
This isn’t just a developer productivity tool. It has direct business implications.
Faster onboarding
New developers don’t spend weeks discovering tribal knowledge through trial and error. Their AI agent already knows conventions, patterns, and standards from day one. Time to first meaningful contribution can drop dramatically.
More consistent code quality
When every AI agent reviews code against the same centrally managed standards, code reviews spend less time catching repetitive style and convention issues and more time on architecture, trade-offs, and product decisions.
Fewer avoidable incidents
A large share of production issues stem from people not knowing the right pattern: the wrong error handler, the missing retry logic, the undocumented security anti-pattern, the forgotten deployment caveat. If every AI agent is aware of the current standards, many of those failure modes can be reduced systematically.
Knowledge doesn’t walk out the door
When a senior engineer leaves, their knowledge stays. It has already been compiled into the wiki. When a team lead moves to a different problem space, the institutional memory remains durable and queryable.
Maintenance cost drops sharply
Traditional wikis decay because nobody wants to maintain them. The update burden grows faster than the perceived value. In this model, the LLM handles the bookkeeping — cross-links, consistency checks, synthesis, gap detection — while humans focus on accuracy, judgement, and governance.
Beyond Engineering: Where Else Could This Work?
The architecture isn’t limited to coding standards. The same pattern — centrally governed, LLM-maintained knowledge served via MCP — applies anywhere an organisation has evolving information that many people, or many AI agents, need to access consistently.
Different flavours of wiki repositories
Platform Engineering Wiki — CI/CD conventions, Terraform patterns, Kubernetes practices, deployment runbooks.
Security & Compliance Wiki — Security policies, APRA or SOX requirements, approved libraries, audit findings, vulnerability remediation guidance.
Architecture Decision Records Wiki — Major technical decisions, why they were made, alternatives considered, and constraints that shaped them.
API & Integration Wiki — Contracts, schemas, integration patterns, rate limits, and error-code standards.
Operational Runbooks Wiki — Incident procedures, escalation paths, thresholds, and known-issue workarounds.
QA & Testing Standards Wiki — Test naming conventions, coverage expectations, mocking patterns, and test data guidance.
Scaling across the enterprise
Each team or domain can maintain its own wiki repository with its own MCP server while sharing a common schema and governance model. A platform team manages infrastructure standards. A security team manages security policies. A data team manages governance rules. Each wiki is independently curated, but every developer’s AI agent can connect to all of them through multiple MCP endpoints.
At enterprise scale, you could even imagine a meta-layer that cross-references standards across domains, flags contradictions between team-specific guidance, and highlights drift. The LLM maintenance model makes this practical in a way purely human-maintained cross-linking rarely is.
What This Is Not
It’s worth being explicit about the boundaries.
This is not RAG. RAG retrieves raw documents and re-derives answers on every query. This model compiles knowledge into structured pages that remain maintained over time.
This is not a chatbot. The wiki itself is not the conversational product. Developer AI agents query it as infrastructure — a tool behind the scenes.
This is not fully automated. Humans review every change to the authoritative wiki. The LLM drafts. Humans approve. The quality gate is non-negotiable.
This is not an implementation guide. I haven’t built this yet. This is an architectural direction I believe is promising, but I want to stress-test it before investing in implementation.
Open Questions I’d Love Feedback On
I’m sharing this because I want to make it stronger before building it. These are the questions I’m actively thinking about:
-
Search at scale: The architecture can start with straightforward keyword search over indexed markdown. At what scale does that break, and what’s the right next step — BM25, semantic search, hybrid retrieval, or something else?
-
Multi-model consistency: Different AI agents interpret instructions differently. How do you write shared
AGENTS.md-style guidance that works well across Codex, Claude, Copilot, Cursor, and Gemini? -
Suggestion quality: A three-vote threshold is a starting heuristic. Too low and admins drown in noise; too high and genuine gaps remain unaddressed. What signal works best?
-
Cross-team governance: When multiple teams have overlapping concerns — for example, security practices that affect everyone — how do you resolve contradictions between domain wikis? Who owns the final word?
-
Measuring value: What metrics would convince a CTO this is working? I’m thinking about time-to-first-PR for new developers, code review turnaround time, incident frequency tied to convention violations, and the trend of unresolved wiki gaps over time.
-
Enterprise adoption: What cultural barriers would slow this down? How do you get senior engineers to trust that the wiki is accurate enough for their agents to rely on?
Over to You
This architecture is inspired by Karpathy’s LLM Wiki pattern, extended for enterprise use with MCP delivery, a guarded developer feedback loop, and a branch strategy that keeps governance clean.
I believe this could meaningfully change how organisations manage and distribute engineering knowledge. But I also assume there are weaknesses I haven’t yet seen — and I’d much rather uncover them now than after building the wrong thing.
If you’re thinking about similar problems — centralised standards, developer enablement, AI-assisted code quality, or simply how to stop losing institutional knowledge — I’d love your perspective.
What would you change? What am I missing? What would break first?
Drop a comment, send a message, or find me on LinkedIn. Let’s refine the idea together.