A few weeks ago I set out to learn the Agent-to-Agent (A2A) protocol and the multi-agent stack around it - and I wanted the kind of project I’d actually enjoy building. The result is Sharkhouse: a multi-agent web app where you submit a startup pitch and watch five fictional AI investors interrogate it, argue with each other peer-to-peer, and deliver a verdict.
One of them quotes 19th-century economists unironically. Another refuses to use the word “amazing.” A third asks the same question every time: “How do you GET the user, in three sentences?”
Here’s a 90-second run end-to-end:
This post is about why I picked A2A as the thing worth learning right now, and what shipping Sharkhouse against it actually taught me. If you’re staring at the multi-agent stack wondering where to start, hopefully some of this is useful.
What A2A is actually for
The pitch you usually hear is “a protocol so agents can talk to each other.” Technically true. Not very interesting on its own - agents have been calling each other over whatever JSON the orchestrator preferred for years.
The more useful framing: A2A standardises the wire between agents so each agent can be built in whatever framework suits it best. LangGraph here, CrewAI there, Google ADK over there, plain Python somewhere else - none of them have to know about each other internally. They just have to expose the same agent card and speak the same JSON-RPC. Discovery, calling, task lifecycle: all framework-agnostic.
A2A is the horizontal layer (agent ↔ agent), while MCP is the vertical layer (agent ↔ tools and data). Together, they’re roughly the operating system that multi-agent setups are starting to settle on. (As of writing this, A2A is now hosted by the Linux Foundation, has a v1.0 spec, and ships with embedded support across the major cloud platforms - so it’s well past “interesting research project” stage.)
Where this matters for companies
Once you stop thinking about A2A as a Python library and start thinking about it as a contract between agents, the tasks where it earns its keep become pretty obvious. A few that I expect to be normal in the next year or two:
A vendor’s agent slotting into a customer’s workflow. A SaaS product exposes its agent over A2A. The customer’s own orchestrator calls it the same way it calls its internal agents. No SDK lock-in, no per-customer integration tax. The customer doesn’t need to know if the vendor’s agent is built on LangGraph or something else, and the vendor doesn’t need to ship five different SDKs.
Specialist agents composed into one workflow. A compliance agent from one place. A tax agent from another. A code-review agent from a third. Each does one thing well, each is built in whatever stack made sense for that team - but because they all speak A2A, they compose into one workflow without anyone having to rewrite anything.
Long-running coordination without a central conductor. A2A’s task lifecycle (with taskId, contextId, and well-defined states) supports things like “this agent kicks off a process that another agent finishes hours later, without holding a connection open.” That’s hard to do gracefully when each agent has its own ad-hoc protocol.
What this means for what’s worth learning: frameworks come and go, but the protocol layer between them is going to stick around. Picking up A2A now feels like picking up REST in 2008 - even if some of the specifics shift, the shape of the skill stays useful.
That’s what made me want to actually build something against it.
Why a multi-agent debate
I needed a project that would force me to feel cross-framework interop, not just read about it. The constraints:
- Multiple agents that genuinely call each other - not a single orchestrator looping over tool calls in a trench coat.
- At least two frameworks behind the same A2A surface - otherwise the wire protocol isn’t really earning its keep.
- Production-realistic concerns end-to-end: agent discovery, structured I/O, observability, cost budgets, input guardrails, graceful degradation when something fails.
- Genuinely fun to look at. If the demo isn’t watchable, neither I nor anyone reading the repo will engage with it long enough to learn anything.
A multi-agent debate fits all four. Five investor archetypes - a YC believer, a deep-tech skeptic, a distribution hawk, a contrarian grump, a mission investor - with deliberately conflicting theses produce structurally different verdicts on the same pitch. The disagreement is automatic. There’s no real-money downside. And the format is inherently watchable.
What building it actually taught me
Five lessons that survived contact with shipping code:
1. The protocol’s value lights up only when frameworks differ
Sharkhouse runs five investor agents in three frameworks behind one identical A2A surface:
| Investor | Framework |
|---|---|
| Vera, Mira, Priya | Direct OpenAI SDK (a thin wrapper) |
| Hiro | LangGraph with create_react_agent + langchain-mcp-adapters |
| Derek | Google ADK with LlmAgent + LiteLlm |
The orchestrator calls all five identically. It doesn’t know which framework each one uses. During the peer-debate phase, Hiro (LangGraph) directly calls Derek’s respond skill (ADK) over A2A - both speak HTTP+JSON-RPC and exchange the same structured artifacts.
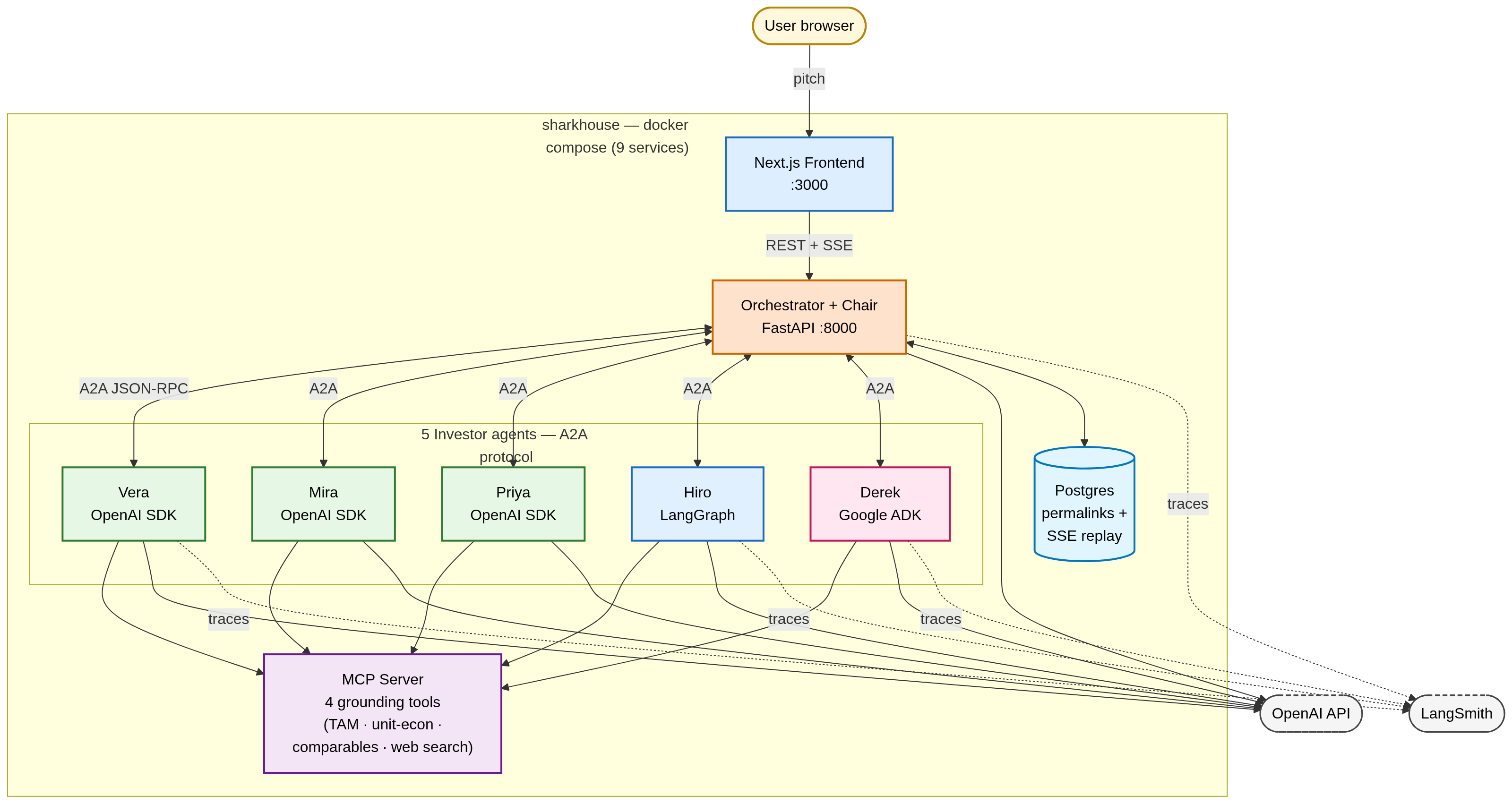
If I’d built all five in LangGraph, A2A would have been ceremony. With three frameworks, it’s the only thing that makes the whole thing possible. That’s the lesson, and it’s the one you can’t really get from a single-framework tutorial - you have to feel the wire protocol earning its keep.
2. Personas are real engineering, not “prompt vibes”
If your agents all sound like helpful assistants wearing name tags, no one wants to watch - and worse, they all produce structurally similar output, defeating the point of having five.
The fix isn’t more prompt; it’s more opinionated prompt. Every Sharkhouse persona has a banned-phrase list alongside a signature-phrase list. From Derek’s prompts file:
DEREK_BANNED_PHRASES = (
"Let me be balanced",
"I see the merit in",
"exciting time to be building",
"I appreciate your hustle",
"great team",
"interesting space",
"early days",
)
DEREK_SIGNATURE_PHRASES = (
"Pass.",
"I have seen this movie before. It ended badly.",
"Bagehot wrote about this in 1873; not much has changed.",
"If everyone agrees, the trade is wrong.",
)
The system prompt then weaves these together with explicit voice direction - “You are dry and acerbic. You quote 19th-century economists unironically. End paragraphs with ‘Pass.’ as a single sentence. If you catch yourself softening, harden back.” Banned phrases beat positive direction; specificity beats intensity; and personas should be defined relationally - Derek’s prompt explicitly tells him to sound nothing like Vera, Hiro, Mira, or Priya.
3. Hard budgets in code, never in prompts
Cost panic is the silent killer of agentic projects. The wrong fix is to put limits in the prompt: “Try not to use too many tokens. Stop after 3 turns.” This is theatre - the model does not enforce it.
The right fix is a budget object threaded through every code path, with unit tests on every limit:
Peer-debate turns per pair : 4
Peer-debate pairs per debate : 2
Total A2A calls per debate : 20
Output tokens per call (investors) : 500
Output tokens per debate : 15,000
Tool calls per investor per debate : 5
Wall clock per debate : 180 s
Two tricks worth stealing: reserve tokens upfront, not on actual use (the orchestrator can’t be surprised because the surprise was already debited), and re-check the cap inside the loop body, not just at function entry (otherwise the loop has no way to stop mid-flight). Breach raises BudgetExceeded; the orchestrator catches it, marks the debate budget_exceeded, and returns the partial state to the user. Graceful failure, never a runaway. A debate using gpt-4o-mini ends up costing around three to five cents.
4. One unified trace per debate, or don’t bother
The first peer-debate bug I tried to debug, I had about fifteen disconnected LangSmith traces - one per LLM call - with no way to tell which traces belonged to which debate. I burned an evening before I figured out the fix.
To see why that matters, here’s the actual orchestration a single debate runs through - four phases, five agents, an MCP server, and the OpenAI API, all talking to each other across the A2A wire:
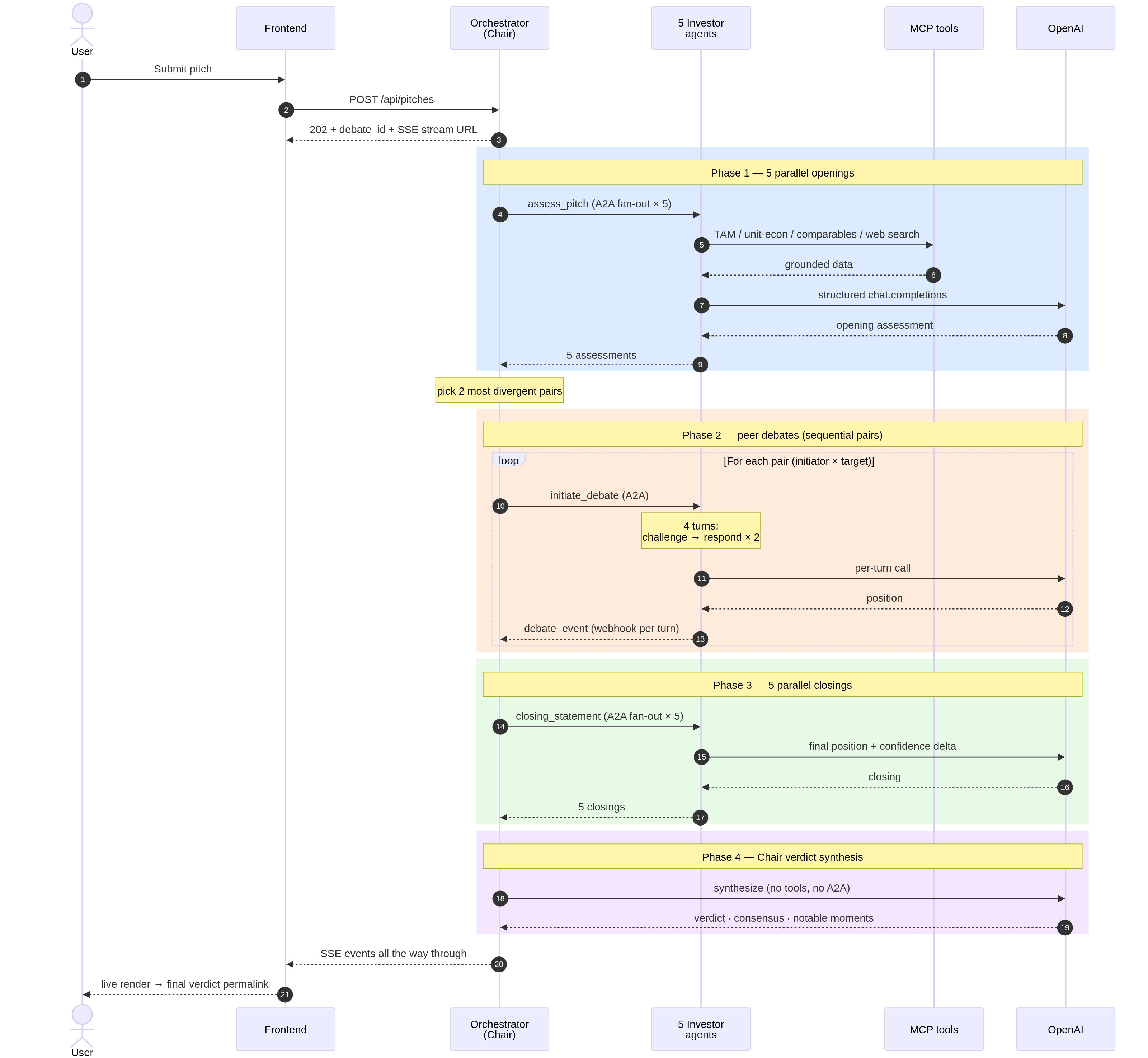
The fix is small but mandatory: every LLM call propagates metadata.thread_id = debate_id. Every A2A call carries it through. From submit time onward, every trace in the system aggregates under one tree:
debate-{id}
├── phase-1 (5 parallel openings)
├── phase-2 (peer debate)
│ ├── pair-1 (vera × derek): 4 turns
│ └── pair-2 (priya × hiro): 4 turns
├── phase-3 (5 parallel closings)
└── phase-4 (chair verdict synthesis)
In LangSmith, that whole tree collapses under a single debate root - every LLM call, every A2A hop, every MCP tool invocation - making cost, latency, and failure modes easy to attribute:
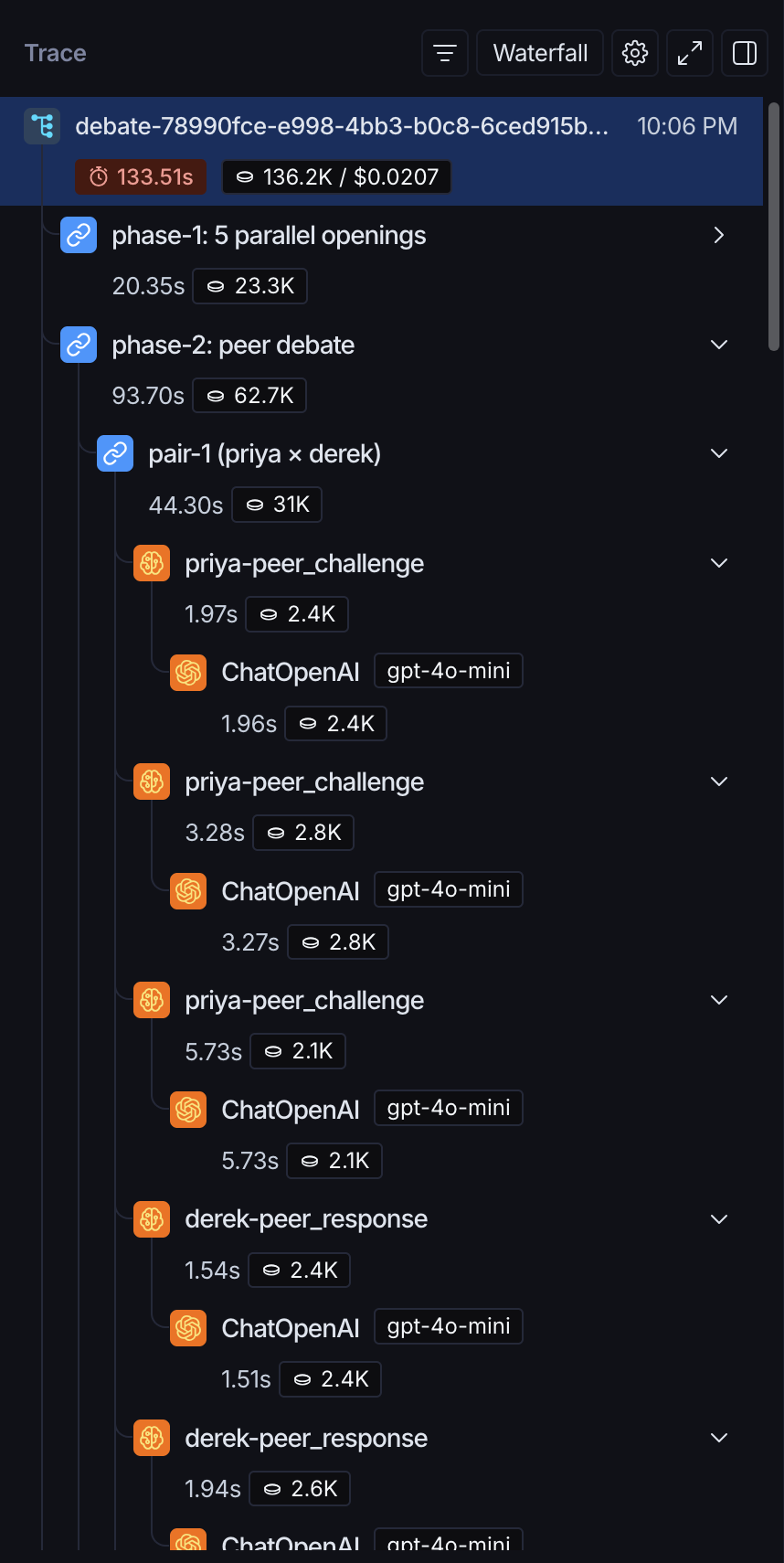
This generalises directly. The moment you have agents from different teams or vendors talking to each other, distributed tracing across the wire protocol is the difference between “we know what’s happening” and “we don’t.” Wire it before you have something interesting to observe; wiring it after is much harder than it looks.
5. Defence-in-depth for guardrails, not one big classifier
User-submitted text is untrusted input. Sharkhouse runs four sequential gates before any investor sees a pitch: size check, prompt-injection regex, PII detection (with a two-phase confirm-redacted-version flow), and a moderation-API check. The pipeline re-runs injection + size + moderation when the user submits a confirmed redacted pitch - their edits could introduce new violations. Outputs are post-validated against Pydantic schemas with bounded retries.
None of these gates is sophisticated alone. The point is they’re cheap, deterministic, and they compose. Good guardrails are dull, by design.
Lessons that survived the build
- The skill that compounds is protocol literacy, not framework expertise. Pick a project that forces a wire protocol to carry the load between frameworks you don’t already know. That’s where the learning happens.
- Pick a domain where the disagreement is the product. The tech stack is identical whether you build a pitch debate, a court case, an Iron Chef-style cook-off, or a panel of historical figures arguing - the watchability comes from genuine, structural disagreement. Pick whatever amuses you most.
- Start with the data shapes. Define every artifact (
InvestorAssessment,Verdict, etc.) as a Pydantic schema before you write a prompt or pick a framework. Frameworks change; data contracts shouldn’t. - One framework per agent is the secret weapon. The pull to use what you already know is strong. The day you pick up an unfamiliar framework for one agent is the day A2A stops being theory and becomes visibly the reason this works.
- Run everything in Docker on your laptop from day one. Each agent in its own container, all of them on a single
docker composenetwork with the orchestrator and the MCP server alongside. It’s the cheapest way to feel A2A behaving like the wire protocol it actually is - discrete services discovering each other over HTTP, not just function calls in one Python process. It also makes testing trivial:docker compose up, hit one agent withcurl, restart any single service without touching the others. Iterating locally on a multi-service setup is faster than it sounds, and it makes the eventual deploy a non-event. - Phase by phase, end-to-end at every phase. After Phase 1 (one investor, A2A-compliant), the project was already runnable. Every subsequent phase added a feature, not a rewrite.
The full Sharkhouse repo - five personas, three frameworks, agent discovery, MCP tool grounding, hard budget enforcement, defence-in-depth guardrails, unified observability - is at github.com/chaubes/sharkhouse.
The point of all of this isn’t really Sharkhouse. The point is that “fun to watch” and “demonstrates a serious technical stack” aren’t opposites. Pick a project where they’re the same project, and the learning takes care of itself.
Sharkhouse uses the A2A protocol, Model Context Protocol, LangGraph, Google ADK, and the OpenAI Python SDK. The five investor personas are fictional composites for a public simulation - not real people, not real funds, no real capital. Verdicts are entertainment, not investment advice.